转载目的:
- 文章确实写好,对于DB2的备份恢复学习很有帮助,非常感谢孙岳
- 用于Markdown练手,学习行文格式
本文以基于 DB2 的 SAP 系统为例,详细介绍了 DB2 备份和恢复的工作原理,以及 DB2 备份和恢复中可以调整的优化参数,并通过 SAP 客户备份和恢复实例来进一步说明如何优化 DB2 备份与恢复的性能,最后讨论了在不同容量下的数据库备份和恢复策略。
DB2 备份和恢复简介
数据库运行过程中可能会遇到诸如存储介质损坏,服务器故障,供电中断等不可预测的问题导致数据丢失或损毁。因此,采取一定备份和恢复策略就显的尤为重要。随着企业用户数据量的不断增长,如何快速而有效的对数据进行备份和恢复,就成为数据库日常维护的重要议题。这也是本文讨论的重点。
下面我们简单介绍 DB2 提供的数据库备份和恢复的方法和命令。DB2 数据库通过 BACKUP DATABASE 和 RESTORE DATABASE 命令来进行数据库的备份和恢复。例如:
db2 “backup database HIA online to E:\backup compress include logs”
db2 “restore database HIA from E:\backup”
DB2 的备份和恢复命令已经被集成进 DB2 引擎。它能够提供不同粒度和不同级别的备份和恢复:
- 完整的数据库或者某个表空间的备份与恢复
- 离线或在线的数据库备份
- 完整、增量或者 delta 方式的数据库备份与恢复
同时,DB2 备份和恢复命令还具有一系列的参数用来调整数据库备份和恢复的效率。例如我们可以通过 UTIL_IMPACT_PRIORITY 参数来调整 DB2 在备份过程中的 CPU 占用率。由于 DB2 备份恢复的参数优化与 DB2 备份和恢复的进程模型具有密切的关系,所以我们首先来看一下 DB2 备份和恢复的工作原理。
DB2 备份和恢复的工作原理
DB2 备份和恢复主要由两种不同的 EDU 共同完成数据库的备份和恢复操作。其中 db2bm(备份和恢复缓冲区操纵程序)用来在表空间和系统缓存间进行数据传输,db2med(备份和恢复介质控制器)用来在系统缓存和外部介质之间进行数据传输。db2bm 和 db2med 均在 db2agent 的协调下进行工作。其中,db2bm 需要通过 db2pfchr(缓冲池预取进程)从容器中预取数据,或者通过 db2pclnr(缓冲池页清楚程序)向容器中写入数据。在 DB2 V9.5 版本之前,db2bm 和 db2med 是以进程方式存在于内存中,而在 DB2 V9.5 版本后改为线程方式。DB2 备份进程模型如下图1所示。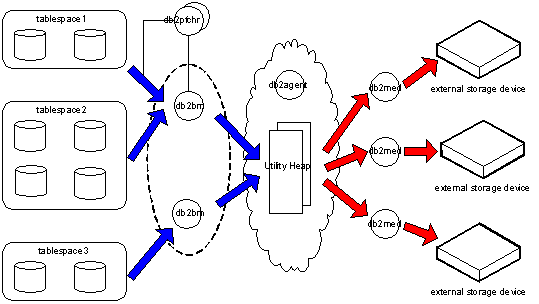
以 DB2 备份为例,从图中我们可以看出,其存在 3 个表空间(tablespace1,tablespace2,tablespace3)和 3 个外部存储介质。第一个 db2bm 进程负责从 tablespace1 和 tablespace2 中顺次读取数据,并将它们写入到系统缓存中。即 db2bm 进程会首先对 tablespace1 进行备份,当备份完成后,db2bm 会开始对 tablespace2 的备份。第二个 db2bm 进程负责从 tablespace3 中读取数据并写入系统缓存。同时,每一个外部存储介质对应于一个 db2med 进程,db2med 进程负责将系统缓存中的数据写入到外部设备中。
DB2 恢复过程与 DB2 备份过程类似,在这里就不再重复解释。如下图 2 所示。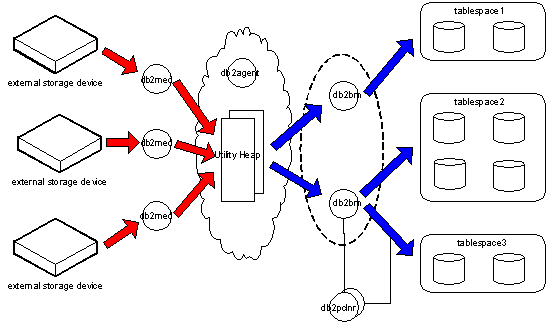
对于 DB2 备份和恢复过程来说,在 EDU 内部,DB2 并不会控制 db2bm 进程从表空间往系统缓存的写入或读取速度,同样的,db2med 进程在系统缓存和外部介质之间的传输速度也不会受到限制。DB2 备份和恢复工具会以尽可能快的速度向外部介质写入和读取数据。我们只能够通过外部参数 UTIL_IMPACT_PRIORITY 对 DB2 备份和恢复进行整体控制。
在 DB2 备份和恢复过程中,每一个表空间都会由一个单独的 db2bm 进程负责读取与写入。如图 1 所示,如果备份过程中存在有 2 个 db2bm 进程,那个其中一个 db2bm 进程会负责对其中的两个表空间进行读写操作。并且这 2 个 db2bm 进程会并行的对表空间进行读写操作,如 tablespace1 和 tablespace3 中的数据会由不同的 db2bm 并行写入到系统缓存。db2bm 的数量可以有 PARALLELISM 参数进行指定,如下。
db2 backup database to d:\backup PARALLELISM 4
db2 restore database from d:\backup PARALLELISM 4
同理,我们可以通过如下的方式指定 db2med 的数目。
db2 backup database to d:\backup e:\backup f:\backup
db2 restore database from d:\backup e:\backup f:\backup
DB2 会根据我们所指定的目标路径的数据来生成对应数据的 db2med 进程。
DB2 备份和恢复的优化参数
本节我们将详细介绍影响 DB2 备份和恢复的优化参数,并结合工作原理解释它们的具体含义,并给出性能优化建议。
BACKUP 优化参数
在 DB2 备份命令中有如下参数可以用来调整数据库备份的性能。
BACKUP DATABASE <DB> TO dir | dev WITH num-buf BUFFERS
BUFFER buff-size PARALLELISM n COMPRESS
UTIL_IMPACT_PRIORITY priority
PARALLELISM n
通过使用 PARALLELISM 参数指定了使用 db2bm 进程数目,它决定了从表空间中往系统缓存中写入的并行性。每一个 db2bm 进程会对应于一个或多个表空间,当一个 db2bm 进程完成对当前表空间的备份后,它会继续对另外一个表空间进行备份。由于每一个 db2bm 进程至少对应于一个表空间,因此 PARALLELISM 值需要小于数据库表空间的数目,如果将设置 PARALLELISM 为大于数据库中表空间的数目,其并不会显著提高备份的性能。
To dir | dev
如果有多个目标路径被指定,如 To dir1, dir2, dir3,则可以指定备份时使用的 db2med 的进程数目。多个 db2med 进程会并行的像 dir1, dir2, dir3 中写入数据,其实第一个目标路径 dir1 中会保存备份数据的数据头以及一些特殊的文件。
如果系统中有多个磁盘系统,可以使用多个目标路径分别指向这些磁盘系统,以提高往磁盘写入数据的并行性。
BUFFER buff-size
使用 BUFFER buff-size 参数可以指定内部缓存的大小,如图 1 中的内部缓存(Utility Heap),单位为 4KB。如果 BUFFER 的值没有指定,则使用 dbm 中的参数 BACKBUFSZ 作为内部缓存的大小。进行备份时,数据首先由表空间写入内部缓存,当缓存满后,缓存中的数据会被写入到外部磁盘中。
BUFFER 值的大小建议设置为 extent 大小的整数倍。如果不同的表空间的 extent 大小不同,则 BUFFER 值建议为它们的最小公倍数。
WITH num-buf BUFFERS
如图 1 所示,每一个备份过程可以拥有一个或者多个内部缓存。将内部缓存的数目设置为至少 db2med 进程的 2 倍能够有效的提高备份时的速度,它使得 db2med 进程向外部磁盘写入数据时无需等待缓存。
同时需要注意的是,(BUFFER buff-size) * (WITH num-buf BUFFERS) < UTIL_HEAP_SZ。UTIL_HEAP_SZ 指定了 DB2 中实用程序堆的大小,此参数指定可由备份、复原和装入(包括装入恢复)实用程序同时使用的最大内存量。
UTIL_IMPACT_PRIORITY
UTIL_IMPACT_PRIORITY 可以用来调节备份的速度,其取值在 1 到 100 之间。1 代表最低优先级,100 代表最高优先级。如果此参数不指定,则备份进程会以最快的速度备份数据。
COMPRESS
备份压缩功能能够在数据写入外部磁盘前,对内部缓存中的数据进行压缩,从而减少备份文件的大小。其使用的是一种改进的 Lempel-Zev(LZ)算法。
通过开启数据压缩功能,我们可以节省存储备份的磁盘空间。例如,在下面的例子中,我们将 SAP 的备份的容量从 89GB 缩小到 13GB。
RESTORE 优化参数
在 DB2 恢复命令中有如下参数可以用来调整数据库恢复的性能。
RESTORE DATABASE <DB> FROM dir | dev WITH num-buf
BUFFERS BUFFER buff-size PARALLELISM n
PARALLELISM n
与 DB2 备份命令相同,PARALLELISM 参数用来指定在恢复过程中的 db2bm 的数目。通过增加 PARRALLELISM 值可以提高数据在内部缓存和表空间之间的并行性。
FROM dir | dev
如果指定多个备份存储路径,(其取决于备份时目标路径的数目)如 From dir1, dir2, dir3,则可以指定恢复时 db2med 进程数目的多少,从而加快数据从外部介质写入内部缓存的速度。
BUFFER buf-size
BUFFER buf-size 的大小为一块内部缓存的大小,其应该设置为 extent 大小的整倍数,同时需要等于或者为备份时所定义大小的整倍数。如果没有设置的话,则使用 dbm 中的 RESTBUFSZ 参数作为内部缓存的大小。
WITH num-buff BUFFERS
指定使用的内部缓存的大小,同备份参数相同,其最好设置为 db2med 的 2 倍以提高备份的速度。同时 (BUFFER buff-size) * (WITH num-buf BUFFERS) < UTIL_HEAP_SZ。
我们可以看到,通过调整 DB2 备份和恢复的参数,我们可以根据当前系统所处的不同硬件环境调整数据库备份和恢复过程中的 db2bm(备份和恢复缓冲区操纵程序)和 db2med(备份和恢复介质控制器)的数目,以及它们在备份和恢复过程中使用的内部缓存的大小和数目等参数,从而提高 DB2 的整体备份和恢复性能。
那么,在具体的环境中,我们如何利用这些参数以提高备份和恢复的性能,就成为我们下面讨论的重点。下一节我们以基于 DB2 的 SAP 系统为例,讨论如何在 SAP 系统中提高备份和恢复的性能,进一步详细说明性能参数在数据库备份和恢复中的影响。
实例 – 在 SAP 系统中进行快速有效的备份和恢复
本节以基于 DB2 的 SAP 系统的备份和恢复为例,通过备份恢复时间,数据库备份和恢复参数的调整与比较等,进一步说明性能参数在数据库备份和恢复中的影响。下文进行备份和恢复的系统硬件环境为 AMD 4 核 CPU,8GB 内存,2 块 IBM SCSI 磁盘作为备份介质,而 SAP 数据库存储在另外 1 块 RAID5 磁盘上。
SAP 系统的备份
通常,SAP 管理员会通过 SAP 中的 DBACockpit 中的 DBA Planning Calendar 对 SAP 的数据库进行备份,或者可以通过业务代码 DB13 直接进入到 DBA Planning Calendar 页面。在 DBA Planning Calendar 里选取 Database Backup to Device 弹出选择画面,如图 3 所示。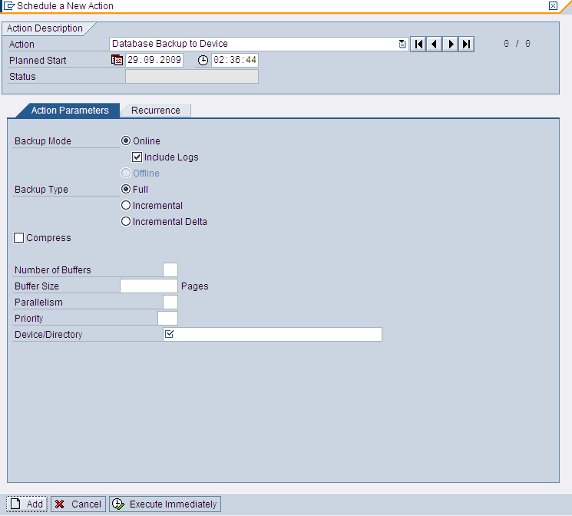
从选择页面中我们可以看到,其提供了备份方式(Backup Mode),备份类型(Backup Type)的选择(关于备份方式和备份类型我们在这里不进行深入的讨论)。其他参数的对应关系如下:
- 压缩(Compress):对应于 DB2 备份命令中的 COMPRESS 参数。
- 内部缓存数目(Number of Buffers):对应于 DB2 备份命令中的 WITH num-buff BUFFERS。
- 内部缓存大小(Buffer Size):对应于 DB2 备份命令中的 BUFFER buf-size,在这里以页为单位(4 KB)。
- 并行数目(Parallelism):对应于 DB2 备份命令中的 PARALLELISM 参数,通过指定该参数可以调整 db2bm 的数目。
- 优先级(Priority):对应于 DB2 备份命令中的 UTIL_IMPACT_PRIORITY,通过它我们可以控制 DB2 进行备份的速度。
- 目标路径(Device/Directory):对应于 DB2 备份命令中的 To dir | dev,通过指定多个目标路径我们可以调整 db2med 的数目。
上面我们已经知道系统具体的硬件环境为 4 核 AMD CPU,8GB 内存,2 块 IBM SCSI 磁盘。那么下面我们通过几组不同的参数比较,来对比一下在不同参数下的 DB2 备份性能。
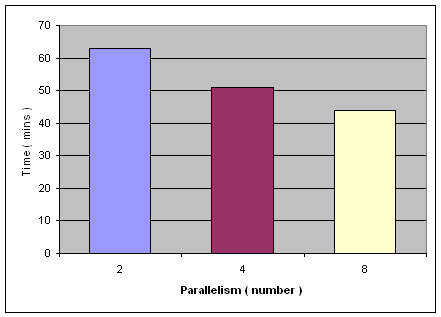
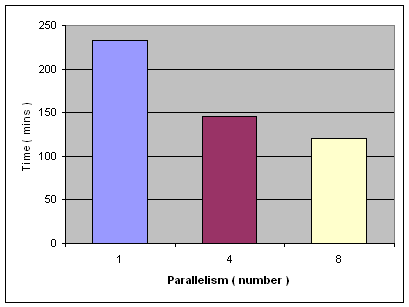
在备份时,比较明显的提高备份速度的方法是改变 PARALLELISM 的值,如我们分别用表 1 中的参数通过 SAP 备份工具进行备份,其中 PARALLELISM 分别等于 2,4 和 8。运行结果如下图 4 所示。从图中我们可以看到,当我们使用 PARALLELISM 为 2 进行备份时,完成整个在线备份的时间大约为 1 个小时。而当使用 PARALLELISM 为 8 时,我们可以将在线备份的时间缩短到 40 分钟左右。因此,通过增加 PARALLELISM 的参数值在一定程度上是可以提高备份速度。
但是,这也并不意味着 PARALLELISM 的值越大越好。我们需要考虑 CPU 的负载能力。例如在本例中,当我们把 PARALLELISM 的值增加到 16 时,备份时间反而增加到 72 分钟。
表 1. PARALLELISM 参数值
| Parallelism | Number of Buffers / Buffer Size | Device / Directory | Compress | Priority |
|---|---|---|---|---|
| 2 | 8 / 1024 | D:\backup | Y | 100 |
| 4 | 8 / 1024 | D:\backup | Y | 100 |
| 8 | 8 / 1024 | D:\backup | Y | 100 |
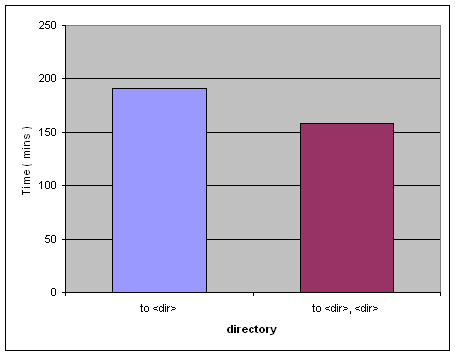
同样,我们也可以通过增加备份的路径数目来提高备份效率。其备份时的参数和结果如下表 2 和图 5 所示。通过结果可以看出,我们也可以通过增加磁盘数目,从而提高磁盘在单位时间内的 I/O 数,来达到提高备份速度的目的。
表 2. To dir | dev 参数值
| Parallelism | Number of Buffers / Buffer Size | Device / Directory | Compress | Priority |
|---|---|---|---|---|
| 1 | 8 / 1024 | D:\backup | Y | 50 |
| 1 | 8 / 1024 | D:\backup, F:\backup | Y | 50 |
另外,通过使用压缩功能也可以提高数据库的备份速度。如下图 6 所示。从图中我们可以看到,采用压缩功能的备份时间要远远小于不压缩的备份时间。由于 DB2 数据压缩功能是在备份时由数据库对缓存中的数据进行实时的压缩,例如:
- 采用压缩的备份文件约为 13 GB
- 不采用压缩的备份文件约为 89 GB
因此它可以有效减小备份文件的大小,即它也减小了备份时对磁盘 I/O 的请求数,因此提高了备份的效率。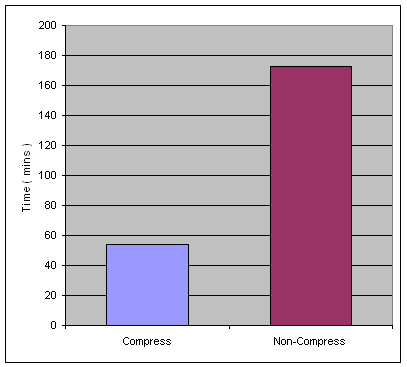
SAP 系统的恢复
在企业应用中进行数据库恢复,通常是当系统出现故障或者其他意外情况导致系统不可用。那么这时就需要我们能够快速的将 SAP 数据库恢复,以减少业务损失。因此,通过调整 RESTORE 参数来提高恢复性能就成为我们十分重要的选择。
我们通过以下的一些实验数据来对调整 RESTORE 参数进行进一步的说明。硬件环境与备份系统的环境相同。
当我们进行 SAP 数据库恢复时,我们可以通过改变 PARALLELISM 的值来提高 DB2 数据库恢复的速度。如图 7 所示,通过如下命令对 SAP 系统的数据库分别进行恢复。我们可以看到,当 PARALLELISM 设置为 8 时(即系统中有 8 个 db2bm 进程同时从表空间读取数据)的恢复时间几乎为 PARALLELISM 等于 1 时的一半。
RESTORE DATABASE HIA FROM d:\bkup WITH 8 BUFFERS BUFFER 1024 PARALLELISM
RESTORE DATABASE HIA FROM d:\bkup WITH 8 BUFFERS BUFFER 1024 PARALLELISM
RESTORE DATABASE HIA FROM d:\bkup WITH 8 BUFFERS BUFFER 1024 PARALLELISM
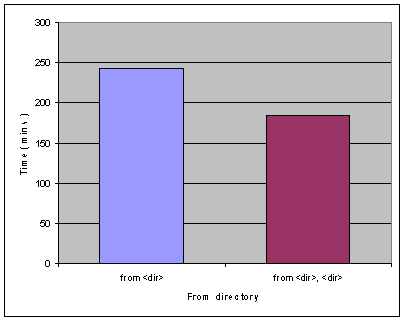
另外,我们也可以通过从多个存储路径中进行数据库恢复,从而提高数据库的恢复速度。如下图 8 所示。我们通过如下的命令从备份文件中恢复数据库。从图 7 中的数据我们可以看出,同时从两个不同的磁盘目录中进行恢复的速度在一定程度上要优于从单一磁盘目录中进行恢复。其原因是在同一时刻,我们可以通过多个磁盘来获取更多的 I/O 数,从而提高备份数据从磁盘读取的速度。但是,这也取决于磁盘每秒钟的 I/O 数和磁盘传输数据的速度,因此,在某些情况下,从多个不同磁盘目录中恢复数据不一定要优于从单一磁盘中恢复。
RESTORE DATABASE HIA FROM d:\bkup
RESTORE DATABASE HIA FROM d:\bkup, f:\bkup
不同容量下的 DB2 备份和恢复策略
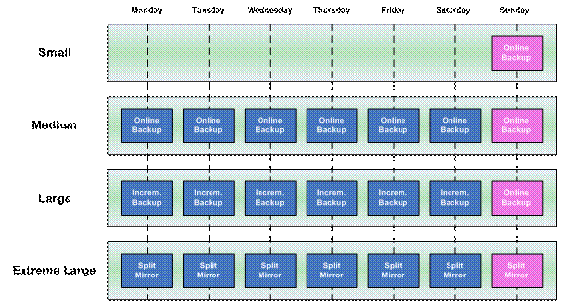
上面我们通过 SAP 系统的备份和恢复实例给出了在不同参数下的 DB2 数据库的备份和恢复性能。但是在企业的实际应用中,通过调整 DB2 的备份和恢复参数不一定能够达到理想的效果。通常,对于不同容量的数据库,我们也需要制定不同的数据库备份和恢复策略,使得我们能够对数据库进行快速的备份和恢复。SAP 推荐的 DB2 数据库备份恢复策略如下图 9 所示。
从下图我们可以看到,SAP 的恢复策略按容量分为小规模应用,中等规模容量,大容量以及极大规模应用:
- 对于开发和测试的 SAP 数据库,我们只需要每周对其进行一次在线备份即可。
- 对于中等规模容量的 SAP 生产系统来说,则我们需要每天进行在线备份。由于它的数据库大小有限,所以一般来说,我们在几个小时之内可以完成对它的在线备份。
- 当数据库容量上升到大规模应用时,那么每天进行在线备份就不是一个好的解决方案。在这种情况下,我们可能很难在几个小时之内完成对数据库的备份,并且会影响到白天正常的业务运转。因此,在每天使用增量备份(Incremental Backup)就成为一种好的选择,它可以减少所需备份的数据量,从而提高备份的速度。同时,我们需要在每个周末进行一次在线备份来对数据库进行完整的备份。
- 当数据库容量继续上升后,使用增量备份也难以对数据库进行快速的备份,那么这时我们就需要使用分割镜像(Split Mirror)技术对数据库进行实时的备份。
结束语
本文介绍了 DB2 数据库备份和恢复的基本工作原理,并对 DB2 数据库备份和恢复的优化参数进行了详细的解释,同时通过在 SAP 系统中对 DB2 数据库的备份和恢复的实例,进一步说明了通过调整优化参数,能够提高在大数据容量下的数据库备份和恢复效率。最后,我们也给出了在不同数据库容量下的数据库备份和恢复策略,供需要规划 SAP 和 DB2 系统备份和恢复的读者参考。
参考资料
学习
- 通过 developerWorks Information Management 专区 学习关于 Information Management 的更多知识。在这里可以找到技术文档、how-to 文章、培训、下载、产品信息等等。
- 通过 Information Management 专区 DB2 9 技术资源中心 了解 DB2 产品家族的更多产品信息和相关技术。
- 通过 DB2 V9.7 信息中心,了解 DB2 的详细产品信息和相关技术等全面的内容。
- 通过 执行数据库备份、恢复和前滚,提供了执行数据库备份、恢复和前滚日志文件这些基本操作的循序渐进指南。
- 通过 IBM DB2 UDB 与 Oracle 的备份和恢复:介绍了 DB2 与 Oracle 数据库中如何进行备份和恢复。
- 通过 执行数据库备份、恢复和前滚,提供了执行数据库备份、恢复和前滚日志文件这些基本操作的循序渐进指南。
- 通过 DB2 基础: IBM DB2 Universal Database for Linux, UNIX and Windows 备份实用程序,介绍了 DB2 备份工具的原理和使用方法。
- 参考“IBM DB2 database and SAP software”,了解更多 DB2 SAP 相关内容。
- 通过 SAP on DB2 for LUW:获得关于 DB2 LUW for SAP 的技术资源及相关文章。
- 随时关注 developerWorks 技术活动 和 网络广播。
获得产品和技术
- 使用可直接从 developerWorks 下载的 IBM 产品评估试用软件 构建您的下一个开发项目。
- 现在可以免费使用 DB2。下载 DB2 Express-C,这是为社区提供的 DB2 Express Edition 的免费版本,它提供了与 DB2 Express Edition 相同的核心数据特性,为构建和部署应用程序奠定了坚实的基础。
讨论
- 通过 SAP COMMUNITY NETWORK:获得 SAP 家族产品和文档资源。
- 通过 SAP SERVICES MARKETPLACE:获得 SAP 产品和服务。SAP 客户可以通过 SAP 客户 ID 访问 SAP NOTES。
- 参与 developerWorks blogs 并加入 developerWorks 中文社区,查看开发人员推动的博客、论坛、组和维基,并与其他 developerWorks 用户交流。